技术人生
旅游
边缘计算
脑电
PMP
项目管理
gazebo
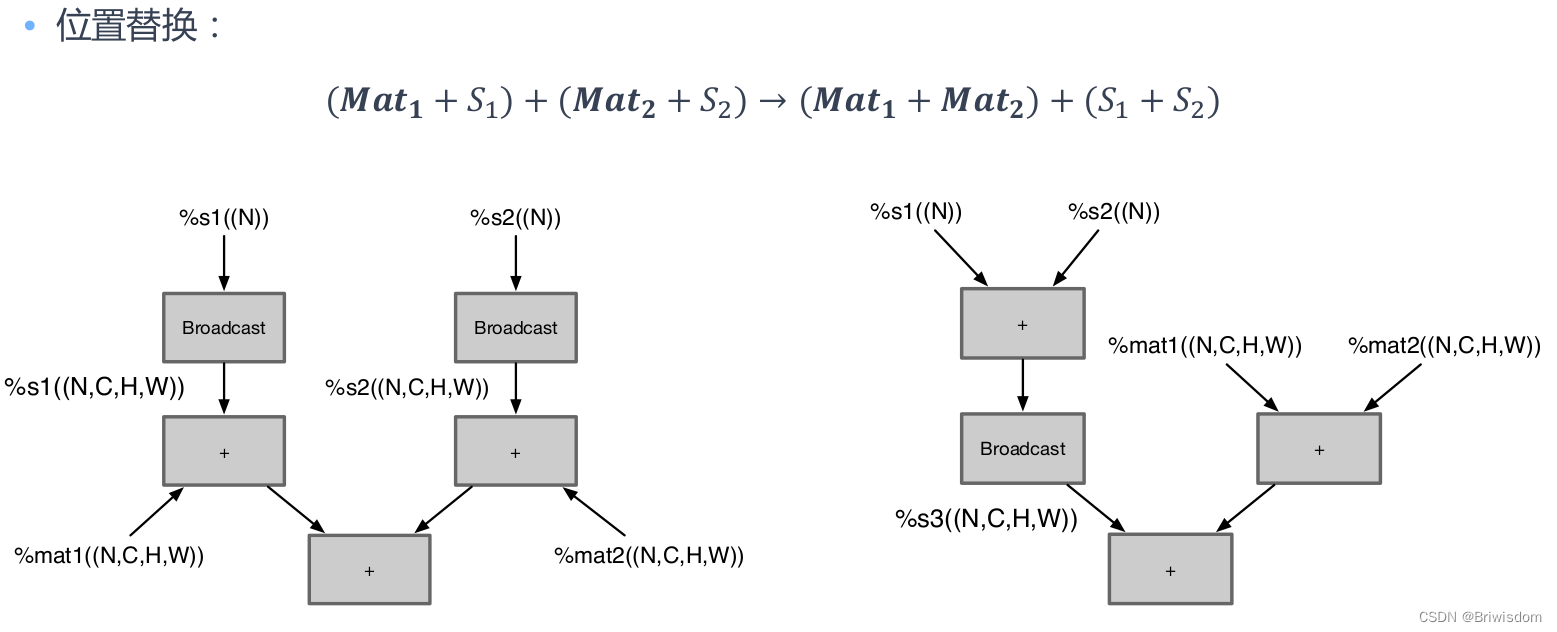
位置编码
华为云应用魔方
mapreduce
端口号
flyfish
azkaban
网上书店
批量制图
舌苔
rbac
轮廓绘制
PLC远程上下载
dalvik
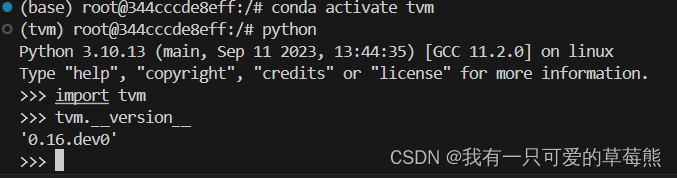
TVM
2024/4/12 5:31:15
【TVM学习六】Install Mxnet on Local Machine (Ubuntu16.04)
pip3 install mxnet
pip3 install --pre gluoncv --upgrade
make USE_OPENCV1 USE_BLASopenblas USE_MKLDNN1# make -j8 ...:
# g: internal compiler error: Killed (program cc1plus) ModuleNotFoundError: No module named gluoncv报错 参考链接:Ubuntu 16.04 …
【TVM学习七】Reproduce Benchmark
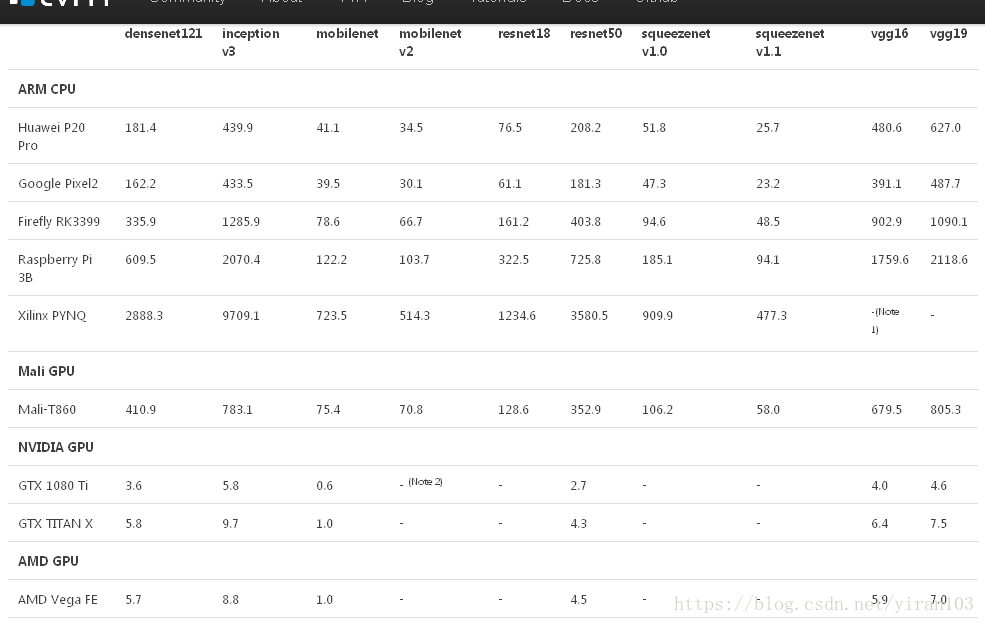
参考链接:Benchmark results How to Reproduce 一. 基于RK3399/ARM-CPU的测试
1. 在本地PC上开启RPC Tracker python3 -m tvm.exec.rpc_tracker 运行完显示如下: INFO:root:If you are running ROCM/Metal, fork will cause compiler internal error. Try to launch with ar…
模型推理加速与部署梳理
推理加速与部署 文章目录 推理加速与部署服务级别的推理加速模型级别的推理加速量化图优化 kernel级别的推理加速GPU常见优化方式特殊Kernel的优化方式 推理框架可供学习的框架 最近学的有点杂,梳理一下我的个人体系,接下来我会花一定时间梳理下面这些东…
tvm交叉编译android可执行参考资料整理
主要参考这个:
TVM部署神经网络模型到android端_tvm android-CSDN博客 其他相关链接:
TVM部署神经网络模型到android端 - 代码先锋网
Ubuntu交叉编译 arm板子上的TVM_tvm arm-CSDN博客
TVM部署神经网络模型到android端 - 代码先锋网
tvm部署c神经网…

线上直播 | 聊聊今年的 TVM Community Keynote
内容一览:TVMCon 2023 终于来咯!今年的大会,我们邀请到了特约嘉宾,线上为大家解读 Apache TVM 接下来的发展规划~
关键词:TVM 中文社区 TVMCon 2023
一年一度的 TVMCon 于北京时间 3 月 16 日凌晨开幕,为…
AI编译器的前端优化策略
背景 工作领域是AI芯片工具链相关,很多相关知识的概念都是跟着项目成长建立起来,但是比较整个技术体系在脑海中都不太系统,比如项目参与中涉及到了很多AI编译器开发相关内容,东西比较零碎,工作中也没有太多时间去做复盘…
编译 PyTorch 模型
本篇文章译自英文文档 Compile PyTorch Models。
作者是 Alex Wong。
更多 TVM 中文文档可访问 →TVM 中文站。
本文介绍了如何用 Relay 部署 PyTorch 模型。
首先应安装 PyTorch。此外,还应安装 TorchVision,并将其作为模型合集 (model zoo)。
可通…
利用 UMA 使硬件加速器可直接用于 TVM
本篇文章译自英文文档 Making your Hardware Accelerator TVM-ready with UMA
作者是 Michael J. Klaiber,Christoph Gerum,Paul Palomero Bernardo。
更多 TVM 中文文档可访问 →TVM 中文站
本节介绍通用模块化加速器接口(UMA)。UMA 提供了一个易用的…
极智AI | 谈谈AI发展第五篇:AI编译框架
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来谈谈 AI编译,是谈谈AI发展系列的第五篇。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 本文是 "谈谈 AI 发展"…
【TVM学习四】基于Linux平台编译TVM—LLVM OpenCL CUDA openblas
参考链接:关于 llvm/clang 在 Ubuntu 下的安装? 补充: 1. 我下载的是LLVM7.0.0版本,对应源码 LLVM source code和Clang source code 2. 在第四步中,进入build目录,执行cmake ../llvm -DCMAKE_BUILD_TYPE=Debug(或者Release) 省略后边: -DLLVM_TARGETS_TO_BUILD=…
【TVM全文翻译】TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
目录
Abstract
1. Introduction
2. Overview
3. Optimizing Computational Graphs
4. Generating Tensor Operations
4.1 Tensor Expression and Schedule Space
TVM Object类型系统
在TVM Object类型系统中最重要的是三个类:Object、ObjectPtr、ObjectRef
为什么需要这三个类?
设计目的:为了能够在不更改python前端的情况下扩展c中的语言对象,且能够对任何语言对象序列化。
Object:编译器中所有的…

自动生成低精度深度学习运算符
以下内容翻译自:Automating Generation of Low Precision Deep Learning Operators 随着深度学习模型变得越来越大,越来越复杂,将它们部署在低功耗手机和物联网设备上变得具有挑战性,因为它们的计算和能源预算有限。深度学习的最新…
深度学习所有硬件平台的自动内核优化
以下内容翻译自:Automatic Kernel Optimization for Deep Learning on All Hardware Platforms 对于 AI 开发人员来说,在各种硬件平台上优化深度神经网络的性能仍然是一个难题。在系统支持方面,我们面临着一个多对多的问题:将多个…

使用 TVM RPC 在手机上远程分析和测试深度学习交叉编译程序
以下内容翻译自:Remote Profile and Test Deep Learning Cross Compilation on Mobile Phones with TVM RPC TVM 堆栈是端到端的编译堆栈,可将深度学习工作负载部署到所有硬件后端。由于 NNVM 编译器支持 TVM 堆栈,我们现在可以直接编译来自深…
【TVM学习一】About TVM
TVM是一个用于CPU, GPU和专用加速器的开放式深度学习编译器堆栈。它旨在缩小以生产力为重点的深度学习框架与面向性能或效率的硬件后端之间的差距。TVM提供以下主要功能: 将Kears, MxNet, Tensorflow, CoreML, DarkNet中的深度学习模型汇编成各种硬件后端的最小可部署模块…

活动预告 | 2023 Meet TVM 开年首聚,上海我们来啦!
内容一览:从去年 12 月延期至今的 TVM 线下聚会终于来了!首站地点我们选在了上海,并邀请到了 4 位讲师结合自己的工作实践,分享 TVM 相关的开发经验,期待与大家线下相聚~ 关键词:2023 Meet TVM 线下活动 自…

通过 DLPack 构建跨框架深度学习编译器
以下内容翻译自:Building a Cross-Framework Deep Learning Compiler via DLPack 诸如 Tensorflow、PyTorch 和 Apache MxNet 等深度学习框架为深度学习的快速原型设计和模型部署提供了强大的工具箱。不幸的是,它们的易用性通常以碎片化为代价࿱…

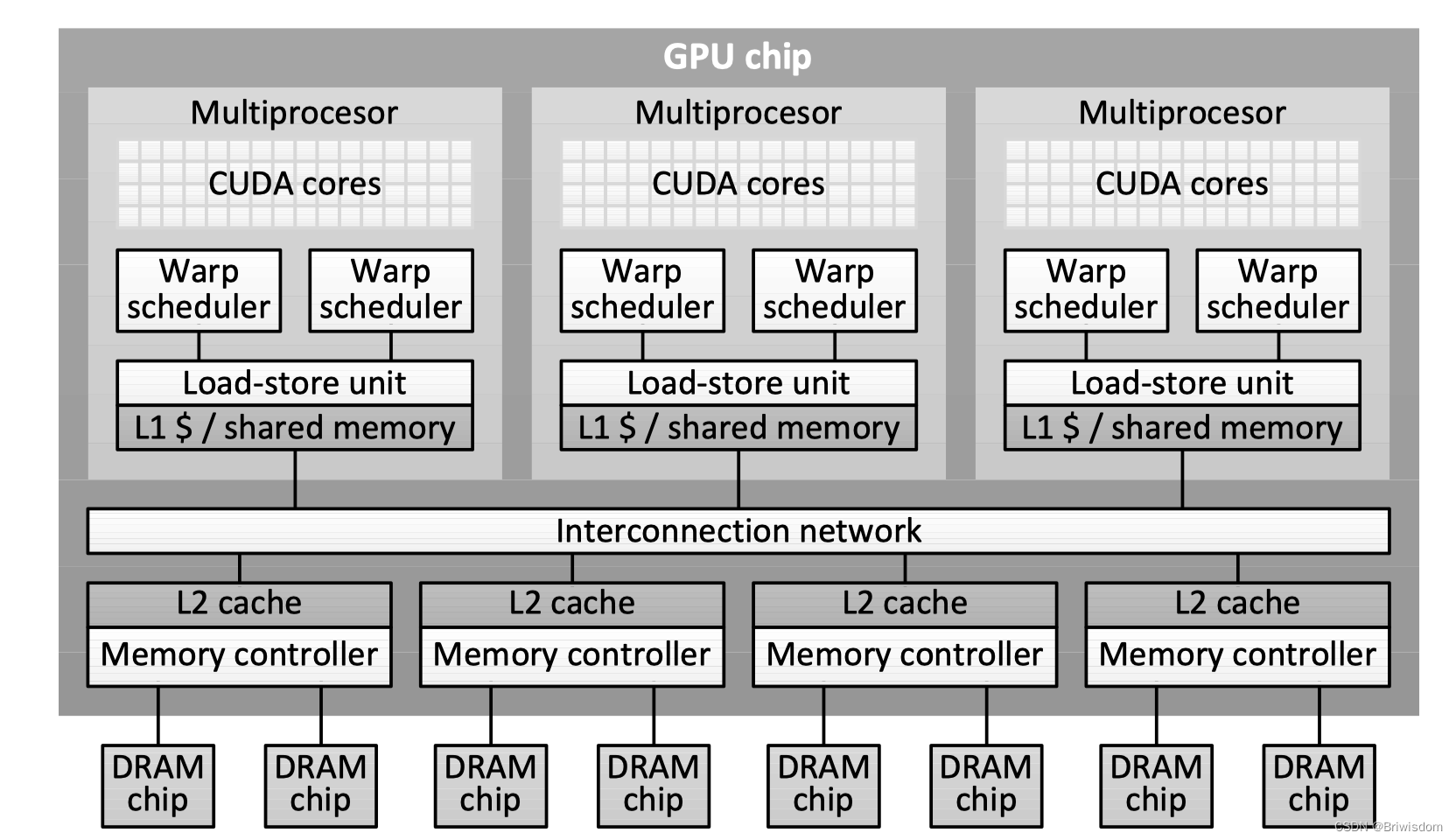
使用TVM优化深度学习GPU算子:深度卷积实例
以下内容翻译自:Optimize Deep Learning GPU Operators with TVM: A Depthwise Convolution Example 高效的深度学习算子是深度学习系统的核心。通常这些算子很难优化,并且需要高性能计算专家的努力。TVM,端到端张量IR/DSL堆栈,使…
在 Android 上部署预训练模型
更多 TVM 中文文档可访问 →https://tvm.hyper.ai/docs
下面是用 Relay 编译 Keras 模型,并将其部署到 Android 设备上的示例:
import os
import numpy as np
from PIL import Image
import keras
from keras.applications.mobilenet_v2 import Mobile…
AI编译器的后端优化策略
背景 工作领域是AI芯片工具链相关,很多相关知识的概念都是跟着项目成长建立起来,但是比较整个技术体系在脑海中都不太系统,比如项目参与中涉及到了很多AI编译器开发相关内容,东西比较零碎,工作中也没有太多时间去做复盘…
tvm交叉编译android opencl
模型编译:
#encoding:utf-8 import onnx
import numpy as np
import tvm
import tvm.relay as relay
import os
from tvm.contrib import ndk onnx_model onnx.load(mobilenet_v3_small.onnx)
x np.ones([1,3,224,224]) input_name …
使用TVMC Python
将使用resnet50 v2模型:
mkdir myscripts
cd myscripts
wget https://github.com/onnx/models/raw/b9a54e89508f101a1611cd64f4ef56b9cb62c7cf/vision/classification/resnet/model/resnet50-v2-7.onnx
mv resnet50-v2-7.onnx my_model.onnx
touch tvmcpythonintro…
Docker环境安装TVM
前提
之前从源码安装过一次TVM,但是要配置cmake,安装llvm等,太过于繁琐,所以这一次准备在Docker镜像里安装TVM,做以记录。
TVM安装 安装docker以及nvidia-docker 参考这篇文章wsl2安装docker以及nvidia-docker安装do…
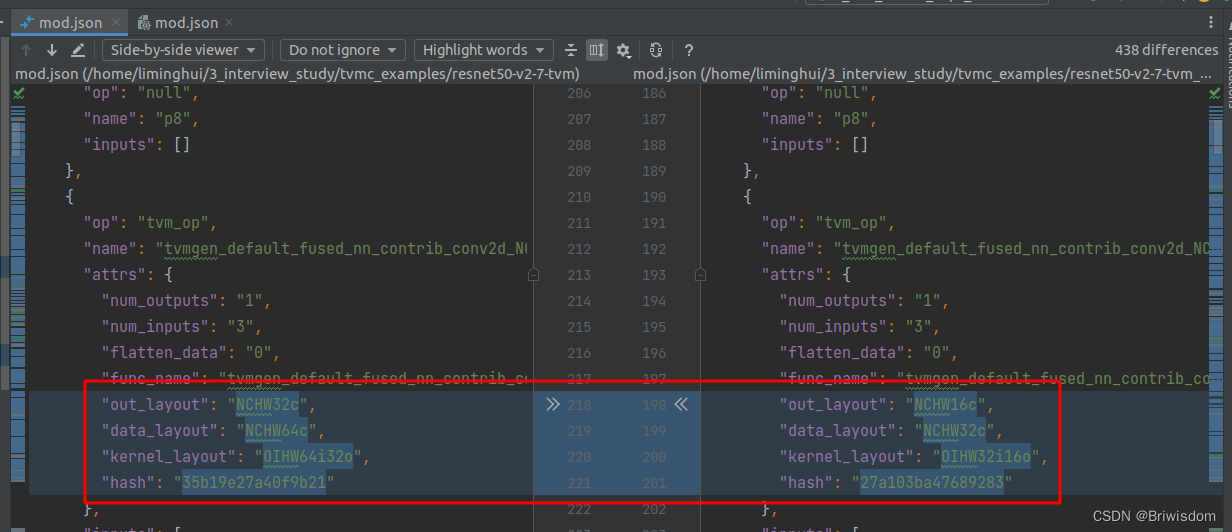
Ubuntu20.04部署TVM流程及编译优化模型示例
前言:记录自己安装TVM的流程,以及一个简单的利用TVM编译模型并执行的示例。 1,官网下载TVM源码 git clone --recursive https://github.com/apache/tvmgit submodule init
git submodule update顺便完成准备工作,比如升级cmake版本…
ubuntu20.04 tvm 安装教程
ubuntu20.04 tvm 安装教程:
参考: 1. https://tvm.hyper.ai/docs/install/from_source/ 2. https://blog.csdn.net/wenwen_2020/article/details/134856293
步骤:
1. 创建容器:docker run -itd --name tvm --gpusall --ipchost…
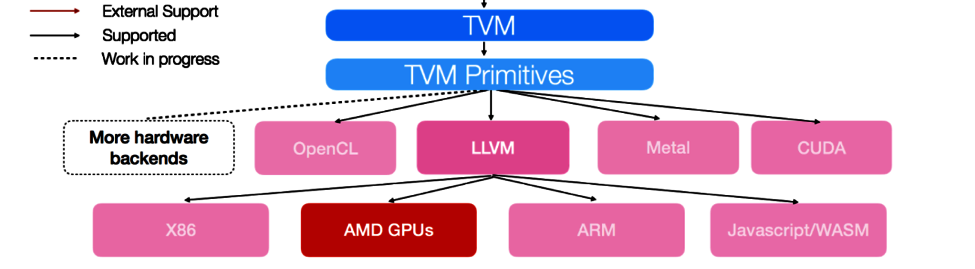
【TVM 学习资料】快速入门:编译深度学习模型
本篇文章译自英文文档 Quick Start Tutorial for Compiling Deep Learning Models 作者是 Yao Wang,Truman Tian。更多 TVM 中文文档可访问→ TVM 中文站
这个例子展示了如何用 Relay Python 前端构建神经网络,并为装有 TVM 的 NVIDIA GPU 生成 runtime 库。注意&a…
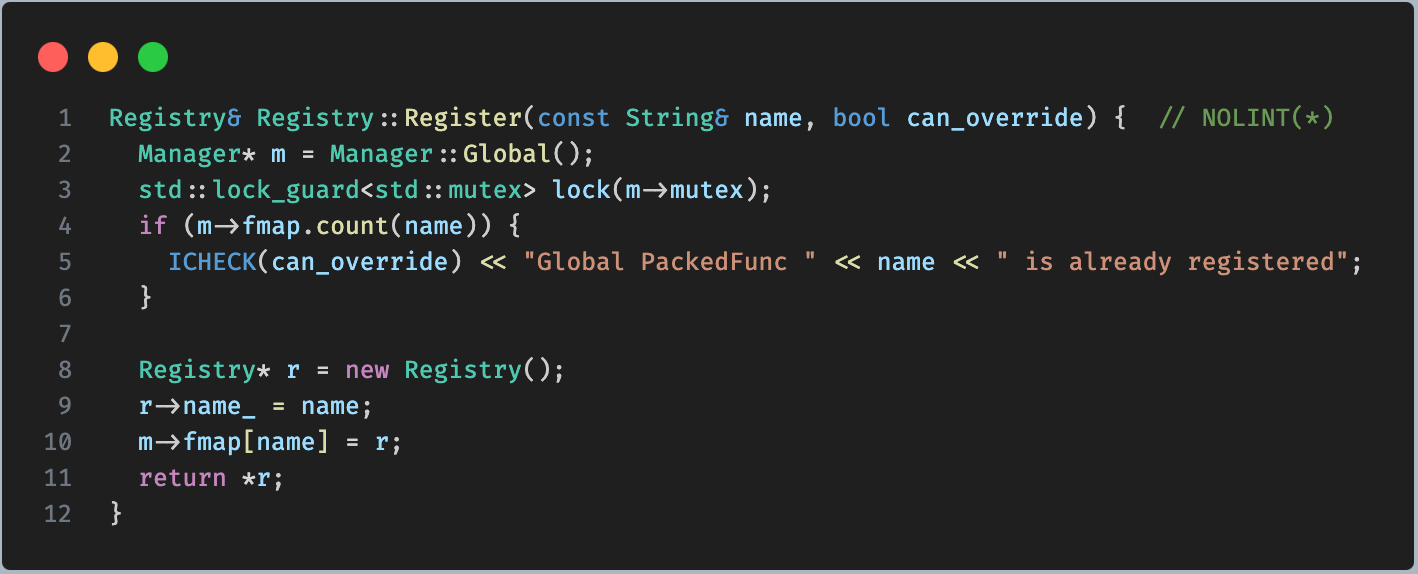
tvm 中的python bindings是如何与 C++ 进行交互的呢
我们知道,tvm 使用 python 作为前端编程语言,好处是 python 简单易用,生态强大,且学习成本较低。而实际的代码,都是 c 代码。 源码编译 tvm,编译完成之后,会在 build 目录下生成 libtvm.so 和 l…

Ubuntu20.04上编译安装TVM
本文主要讲述如何在ubuntu20.04平台上编译TVM代码并在python中import tvm成功。
源代码下载: git clone --recursive https://github.com/apache/tvm tvm 平台环境升级: 1) sudo apt-get update 2) sudo apt-get install -y pyth…
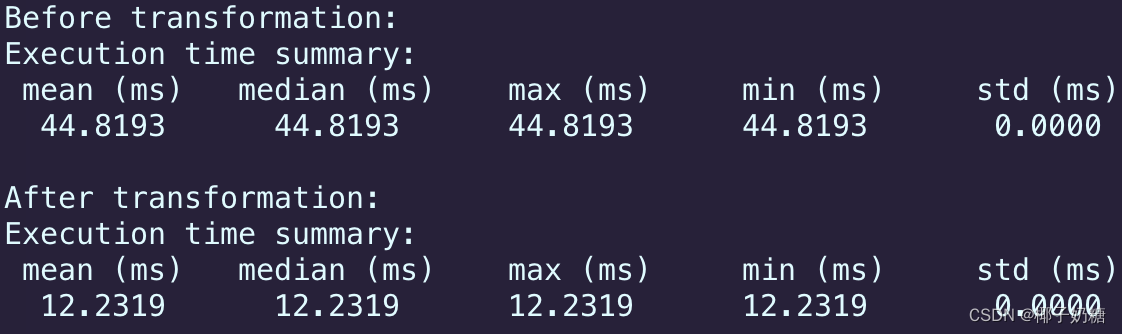
【MLC】 TensorIR 练习
文章目录 前言TensorIR 练习TensorIR: 张量程序抽象案例研究练习 1:广播加法练习 2:二维卷积练习 3:变换批量矩阵乘法程序 总结 前言
这两天重新看了一下天奇的mlc课程文档,把里边儿的TensorIR 练习写了一下,顺便推广…

TVM 中文站正式上线!最全机器学习模型部署「参考书」它来了
内容一览: 近日,由 MLC 社区志愿者共同翻译校对的 TVM 中文文档正式发布,现已托管至超神经官网 Hyper.AI。 关键词: TVM 开源 机器学习编译器 本文首发自微信公众号:HyperAI超神经 面世5年,TVM成备受追捧的…
【TVM学习五】Install TVM on Local Machine (Ubuntu16.04)
参考链接:https://docs.tvm.ai/install/from_source.html#python-package-installation 补充: 1. Edit build/config.cmake to customize the compilation options,在这一步中将编译好的llvm-build路径加进去: set(USE_LLVM /path/to/your/llvm-build/bin/llvm-config) 2. …
tvm android_rpc_test.py执行报错解决
执行 python3 tests/android_rpc_test.py 报错:
Run CPU test ... Traceback (most recent call last): File "tests/android_rpc_test.py", line 129, in <module> test_rpc_module() File "tests/android_rpc_test.py", line …